Introduction
As I reported in my previous post on 31st July, the model I use, originally authored by Prof. Alex de Visscher at Concordia University in Montreal, and described here, required an update to handle several phases of lockdown easing, and I’m glad to say that is now done.
Alex has been kind enough to send me an updated model code, adopting a method I had been considering myself, introducing an array of dates and intervention effectiveness parameters.
I have been able to add the recent UK Government relaxation dates, and the estimated effectiveness of each into the new model code. I ran some sensitivities which are also reported.
Updated interventions effectiveness and dates
Now that the model can reflect the timing and impact of various interventions and relaxations, I can use the epidemic history to date to calibrate the model against both the initial lockdown on March 23rd, and the relaxations we have seen so far.
Both the UK population (informally) and the Government (formally) are making adjustments to their actions in the light of the threats, actual and perceived, and so the intervention effects will vary.
Model adjustments
At present I am experimenting with different effectiveness percentages relating to four principal lockdown relaxation dates, as described at the Institute for Government website.
In the model, the variable k11 is the starting % infection rate per day per person for SARS-Cov-2, at 0.39, which corresponds to 1 infection every 1/0.39 days ~= 2.5 days per infection.
Successive resetting of the interv_success % model variable allows the lockdown, and its successive easings to be defined in the model. 83.5% (on March 23rd for the initial lockdown) corresponds to k11 x 16.5% as the new infection rate under the initial lockdown, for example.
In the table below, I have also added alternative lockdown easing adjustments in red to show, by comparison, the effect of the forecast, and hence how difficult it will be for a while to assess the impact of the lockdown easings, volatile and variable as they seem to be.
| Date | Day | Steps and example measures | Changes to % effectiveness |
|---|---|---|---|
| 23rd March | 52 | Lockdown starts | +83.5% |
| 13th May | 105 | Step 1 – Partial return to work Those who can work from home should do so, but those who cannot should return to work with social distancing guidance in place. Some sports facilities open. | -1% = 82.5% -4% = 79.5% |
| 1st June | 122 | Step 2 – Some Reception, Year 1 and Year 6 returned to school. People can leave the house for any reason (not overnight). Outdoor markets and car showrooms opened. | -5% = 77.5% -8% = 71.5% |
| 15th June | 136 | Step 2 additional – Secondary schools partially reopened for years 10 and 12. All other retail are permitted to re-open with social distancing measures in place. | -10% = 67.5% +10% = 81.5% |
| 4th July | 155 | Step 3 – Food service providers, pubs and some leisure facilities are permitted to open, as long as they are able to enact social distancing. | +20% = 87.5% -6% = 75.5% |
| 1st August | 186 | Step 3 additional – Shielding for 2m vulnerable people in the UK ceases | 0% = 87.5% |
After the first of these interventions, the 83.5% effectiveness for the original March 23rd lockdown, my model presented a good forecast up until lockdown easing began to happen (both informally and also though Government measures) on May 13th, when Step 1 started, as shown above and in more detail at the Institute for Government website.
Within each easing step, there were several intervention relaxations across different areas of people’s working and personal lives, and I have shown two of the Step 2 components on June 1st and June 15th above.
I applied a further easing % for June 15th (when more Step 2 adjustments were made), and, following Step 3 on July 4th, and the end (for the time being) of shielding for 2m vulnerable people on August 1st, I am expecting another change in mid-August.
I have managed to match the reported data so far with the settings above, noting that even though the July 4th Step 3 was a relaxation, the model matches reported data better when the overall lockdown effectiveness at that time is increased. I expect to adjust this soon to a more realistic assessment of what we are seeing across the UK.
With the % settings in red, the outlook is a little different, and I will show the charts for these a little later in the post
The settings have to reflect not only the various Step relaxation measures themselves, but also Government guidelines, the cumulative changes in public behaviour, and the virus response at any given time.
For example, the wearing of face coverings has become much more common, as mandated in some circumstances but done voluntarily elsewhere by many.
Comparative model charts
The following charts show the resulting changes for the initial easing settings. The first two show the new period of calibration I have used from early March to the present day, August 4th.
On chart 4, on the left, you can see the “uptick” beginning to start, and the model line isn’t far from the 7-day trend line of reported numbers at present (although as of early August possibly falling behind the reported trend a little).


On the linear axis chart 13, on the right, the reported and model curves are far closer than in the version in my most recent post on July 31st, when I showed the effects of lockdown easing on the previous forecasts, and I highlighted the difficulty of updating without a way of parametrising the lockdown easing steps (at that time).
Using the new model capabilities, I have now been able to calibrate the model to the present day, both achieving the good match I already had from March 23rd lockdown to mid-May, and then separately to adjust and calibrate the model behaviour since mid-May to the present day, by adjusting the lockdown effectiveness at May 15th, June 1st, June 15th and July 4th, as described earlier.
The orange dots (the daily deaths) on chart 4 tend to cluster in groups of 4 or 5 per week above the trend line (and also the model line), and 3 or 2 per week below. This is because of the poor accuracy of some reporting at weekends (consistently under-reporting at weekends and recovering by over-reporting early the following week).
The red 7-day trend line on chart 4 reflects the weekly average position.
Looking a little further ahead, to September 30th, this model, with the initial easing settings, predicts the following behaviour, prior to any further lockdown easing adjustments, expected in mid-August.

Finally, for comparison, the Worldometers UK site has a link to its own forecast site, which has several forecasts depending on assumptions made about mask-wearing, and/or continued mandated lockdown measures, with confidence limits. I have screenshot the forecast on October 1st, where it shows 48,268 deaths assuming current mandates continuing, and mask-wearing.
My own forecast shows 47,201 cumulative deaths at that date.

Alternative % settings in red
I now present a slideshow of the corresponding charts with the red % easing settings. The results here are for the same initial lockdown effectiveness, 83.5%, but with successive easings at -4%, -8%, +10% and -6%, where negative is relaxation, and positive is an increase in intervention effectiveness.

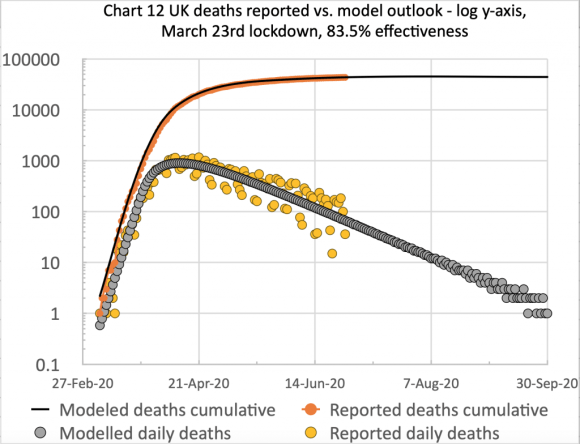
Chart 12 for the comparison of cumulative & daily reported & modelled deaths to 26th April 2021, adjusted by -4%, -8% +10% and -6% 
Chart 12 for the comparison of cumulative & daily reported & modelled deaths to 30th Sep, adjusted by -4%, -8% +10% and -6% 
Chart 4 comparison of cumulative & daily reported & modelled deaths, & reported trend line, for 83.5% effectiveness, adjusted by -4%, -8% +10% and -6% 
Model forecast for the UK and reported deaths as at August 8th, for 83.5% lockdown effectiveness, adjusted by -4%, -8% +10% and -6% 
Model forecast (linear axes) and reported UK deaths to August 8th, for 83.5% lockdown effectiveness, adjusted by -4%, -8% +10% and -6%
The model forecast here for September 30th is for 49, 549 deaths, and the outlook for the longer term, April 2021, is for 52,544.
Thus the next crucial few months, as the UK adjusts its methods for interventions to be more local and immediate, will be vital in its impact on outcomes. The modelling of how this will work is far more difficult, therefore, with fine-grained data required on virus characteristics, population movement, the comparative effect of different intervention measures, and individual responses and behaviour.
Hotspots and local lockdowns
At present, because the UK reported case number trend has flattened out and isn’t decreasing as fast, and because of some local hotspots of Covid-19 cases, the UK Government has been forced to take some local measures, for example in Leicester a month ago, and more recently in Manchester; the scope and scale of any lockdown adjustments is, therefore, a moving target.
I would expect this to be the pattern for the future, rather than national lockdowns. The work of Adam Kucharski, reported at the Wellcome Open Research website, highlighting the “k-number”, representing the variation, or dispersion in R, the reproduction number, as he says in his Twitter thread, will be an important area to understand.
The k-number might well be more indicative, at this local hotspot stage of the crisis, than just the R reproduction number alone; it has a relationship to the “superspreader” phenomenon discussed for SARS in this 2005 paper, that was also noticed very early on for SARS-Cov-2 in the 2020 pandemic, both in Italy and also in the UK. I will look at that in more detail in another posting.
Superspreading relates to individuals who are infected (probably asymptomatically or pre-symptomatically) who infect others in a closed social space (eg in a ski resort chalet as reported by the BBC on February 8th) without realising it.
The hotspots we are now seeing in many places might well be related to this type of dispersion. The modelling for this would be a further complication, potentially requiring a more detailed spatial model, which I briefly discussed in my blog post on modelling methods on July 14th.
Superspreading might also need to be understood in relation to the opening of schools, in August and September (across the four UK home countries). It might have been a factor in Israel’s experience of return to schools, as covered by the Irish Times on August 4th.
The excess deaths measure
There has been quite a debate on excess deaths (often a seasonal comparison of age-related deaths statistics compared with the previous 5 years) as a measure of the overall position at any time. As I said in a previous post on June 2nd, this measure does mitigate any arguments as to what is a Covid-19 fatality, and what isn’t.
The excess deaths measure, however, has its own issues with regard to the epidemic’s indirect influence on the death rates from other causes, both upwards and downwards.
Since there is less travel (on the roads, for example, with fewer accidents), and many people are taking more care in other ways in their daily lives, deaths from some other causes might tend to reduce.
On the other hand, people are feeling other pressures on their daily lives, affecting their mood and health (for example the weight gain issues reported by the COVID Symptom Study), and some are not seeking medical help as readily as they might have done in other circumstances, for fear of putting themselves at risk of contracting Covid-19. Both factors tend to increase illness and potentially death rates.
Even as excess deaths reduce, then, it may well be that Covid-19 deaths increase as others reduce. Possibly a crossover with seasonal influenza deaths, later on, might be masked by the overall excess deaths measure.
As I also mentioned in my post on July 6th, deaths in later years from other causes might increase because of this lack of timely diagnosis and treatment for other “dread” diseases, as, for example, for cancer, as stated by Data-can.org.uk.
So no measure of the epidemic’s effects is without its issues. Prof. Sir David Spiegelhalter covered this aspect in a newspaper article this week.
Discussion
The statistical interpretation and modelling of data related to the pandemic is a matter of much debate. Some commentators and modellers are proponents of quite different methods of data recording, analysis and forecasting, and I covered phenomenological methods compared with mechanistic (SIR) modelling in previous posts on July 14th and July 18th.
The current reduced rate of decline in cases and deaths in some countries and regions, with concomitant local outbreaks being handled by local intervention measures, including, in effect, local lockdowns, has complicated the predictions of some who think (and have predicted) that the SARS-Cov-2 crisis will soon be over (some possibly for political reasons, some of them scientists).
Even when excess deaths reduce to zero, this doesn’t mean that Covid-19 is over, because, as I mentioned above, illness and deaths from other causes might have reduced, with Covid-19 filling the gap.
There are also concerns that recovery from Covid-19 as a death threat can be followed by longer-lasting illness and symptoms, and some studies (for example this NHLBI one) are gathering evidence, such as that covered by this report in the Thailand Medical News.
This Discharge advice from the UK NHS makes continuing care requirements for discharged Covid-19 patients in the UK very clear.
It is by no means certain, either, that recovery from Covid-19 confers immunity to SARS-Cov-2, and, if it does, for how long.
Concluding comments
I remain of the view that in the absence of a vaccine, or a very effective pharmaceutical treatment therapy, we will be living with SARS-Cov-2 for a long time, and that we do have to continue to be cautious, even (or, rather, especially) as the UK Government (and many others) move to easing national lockdown, at the same time as being forced to enhance some local intervention measures.
The virus remains with us, and Government interventions are changing very fast. Face coverings, post-travel quarantining, office/home working and social distancing decisions, guidance and responses are all moving quite quickly, not necessarily just nationally, but regionally and locally too.
I will continue to sharpen the focus of my own model; I suspect that there will be many revisions and that any forecasts are now being made (including by me) against a moving target in a changing context.
Any forecast, in any country, that it will be all over bar the shouting this summer is at best a hostage to fortune, and, at worst, irresponsible. My own model still requires tuning; in any case, however, I would not be axiomatic about its outputs.
This is an opinion informed by my studies of others’ work, my own modelling, and considerations made while writing my 30 posts on this topic since late March.